Event Driven Client Management
A consideration on a code based, scalable, event driven client management framework…
What are we trying to accomplish here?
I investigate the situation where we, as system administrators, find ourselves in a vastly SaaS driven world which derives many points of truth from across many different systems. How do we manage those things centrally? How do we shift from an actively managed posture, to a passive (or event driven posture), and is there a way to meet in the middle? Is there “one tool to rule them all” or are we siloed by platform? I think to pull myself back, I am just going to outline this idea, conclusion and how I arrived at it in terms of macOS and how we can embrace the inevitable, and build systems around what is currently the “only way” to manage macOS devices. And to do that we must…
Understand the macOS management ecosystem and its current trajectory
Apple has set the direction with managing macOS devices. What I try to reiterate to folks in conversation is that the MDM spec is the MDM spec. Meaning Apple, like everywhere else in their ecosystem is defining the “rules of the game” to interact with their devices in a managed way. When setting out to “look for an mdm” I think it’s good to constantly remind yourself that it’s the same set of API calls from the biggest to the smallest vendor, Apple only gives you a defined amount of tooling, anything else is fluff. Not saying fluff isn’t helpful, but fluff is fluff and not core to device management implications.
If we step back and look for an MDM vendor that 1.) works well, especially at the scale you’re operating and 2.) has the ability to be extensible to your desire. That path of discovery will look a lot different for a lot of people, and that’s okay, “live your truth”. I make the argument that being extensible is having an actively under development and functioning API. A good API is, in my opinion, the best feature a vendor can offer.
Why is that the best feature? I am approaching this from a perspective where we treat not only “infrastructure as code” but client “configuration as code” as well. Something increasingly difficult to do when Apple is gating particular controls that can be managed of devices via an MDM. Having an API allows for the possibility of settings being managed in a systematic way, via some system. I realize this isn’t something everyone wants, and a small business managing a few dozen machines is completely doable in a good web interface. Where this is very beneficial is when you start approaching thousands of clients and the idea of client “configuration as code” piece really begins to have benefits.
As Apple shifts this control and requirements to MDM only, this means for those items in place we are reliant on our MDM first and foremost, which is then in turn reliant on Apple and the MDM framework. The reliability and visibility into anything past what your MDM offers is minimal, to any and all vendors, and that’s just a reality of the current ecosystem in place. How do we function within those constraints while also having the ability to add robustness and logic driven workflows? In short, how do we build a flexible glue between our systems to both adhere to this new paradigm as well as have the benefits of a code driven environment? That’s what I want to know as well, and what led me on this thought experiment.
What if client management wasn’t linear?
I remember watching some videos on AWS’s EventBridge after it got announced and thinking “huh, that could be cool”, as most of my bad ideas start out. If you’re not familiar with AWS Event Bridge you can learn more here. In short it’s a central flow of json “events” (logs) that can adhere to a predefined schema, this schema you can then trigger other AWS services is a pattern match in that schema is found. The idea is that you can scale out actions horizontally, independently and quickly to other AWS services. A successor to a more linear SQS or SNS queue, arguably fulfilling an entirely different role, but I digress.
This “bad idea” was in fact, “What if client management wasn’t linear?” What if we shifted from treating the management hierarchy as config -> apply -> remediate and looked at clients as nodes within a greater ecosystem, going through various stages of their own life cycle, and allowing events that these nodes “emote” determine other actions that happen within the management ecosystem?
So it’s just a big if this then that?
Yes! No! Well sort of… isn’t all code? It would be more like a “if this then that and that and that or that and if… and if…” An oversimplification of this idea is a single stream of events propagated from any system in regards to a device, or node. From that single stream of events, we can delve into the events, in near real time, pick and choose what actions we want to take, all while archiving these node specific events for evaluating trends. This seems huge, adn overwhelming, and it was/is! The benefit of this design is you can start with the smallest process or flow and add and grow the interactions in this framework as needed, approaching it at a micro, rather than a macro, scale.
I think the idea in general is not limited to AWS or EventBridge, conceptually you could extend this idea, or framework, to any system that can parse incoming data, and then perform actions based on said triggers, such as initiating webhooks via a logging tool. I will keep exploring this framework through the lens of AWS and it’s available tooling, but in no way is that the only path to implementing this idea/framework.
To begin, we start in the middle.
The core idea of EventBridge is that there is a defined JSON schema. AWS EventBridge Schema and Registry options are quite robust, so for sake of illustration we will define our schema with some actions we wish to perform. In the life of our node we can expect lots of things to happen, but at the very core of what happens to a node, what do we want? We want to know about the event, we want to perform an action because of the event, we want to keep record of the event historically and we want to be able to look at a high level of events looking for trends.
Hey listen!
By default, any event in an Event Bridge does nothing. It effectively goes to /dev/null unless a rule is triggered. So getting started the best way to have some visibility is to set a blanket rule for any, or a subset meeting an event pattern, to send the events to Cloudwatch. You can configure a target of a specific Cloudwatch log group to receive any/all of the events. A good way to ensure the events are hitting the event bus at all.
By each extension, each trigger could have its own target log group, or you could have a blanket catch-all log group for any event passing through an event bus, that design choice is really up to you and the complexity of the event based triggers, and the desired level of visibility. You could also set a lambda target that transforms the event payload to GELF or some other logging specific format and then ships it to a unified logging service you may have at your utilization. Or perhaps just setting the TTL on cloudwatch to be a few weeks but also sending the logs to an s3 bucket for long term retention? All possibilities.
Do the thing-
What thing? All the things? AWS Event Bridge logic has an ever expanding list of available targets:
- API destination
- API Gateway
- AWS Batch job queue
- CloudWatch Logs group
- CodeBuild project
- CodePipeline
- Amazon ECS tasks
- Event bus in a different account or Region
- Firehose delivery stream (Kinesis Data Firehose)
- Inspector assessment template (Amazon Inspector)
- Kinesis stream (Kinesis Data Streams)
- AWS Lambda function
- …
Wowza, that’s a lot of services (and only some of the supported ones), and it makes my head spin with the possibilities. From a system administration perspective we can utilize our event bus as just that, a single place for passing and triggering off events we care about. Will it be something for passive analysis? No. But the ability to integrate with Kinesis opens a lot of doors in that realm.
So what could this look like?
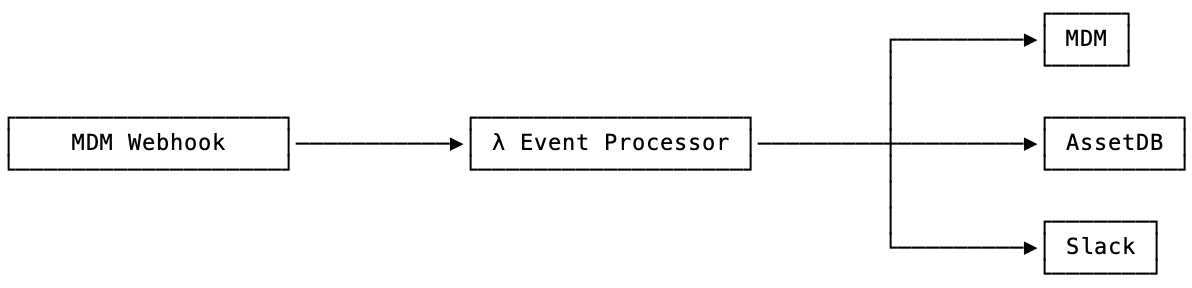
Starting off will be an illustration of a basic scenario, a device enrolls. Assuming your MDM of choice has the ability to support webhooks, you could receive that payload via API Gateway, process via Lambda, and turn around and invoke change, nothing new and a fair amount of tooling and processes exist around this idea.
In this thought experiment I want to have a less direct invocation, but the ability to process this event and then have multiple subsets of services fan out doing the needed actions for this event. So rather than a single Lambda function that is responsible for all the processing and logic of an event.
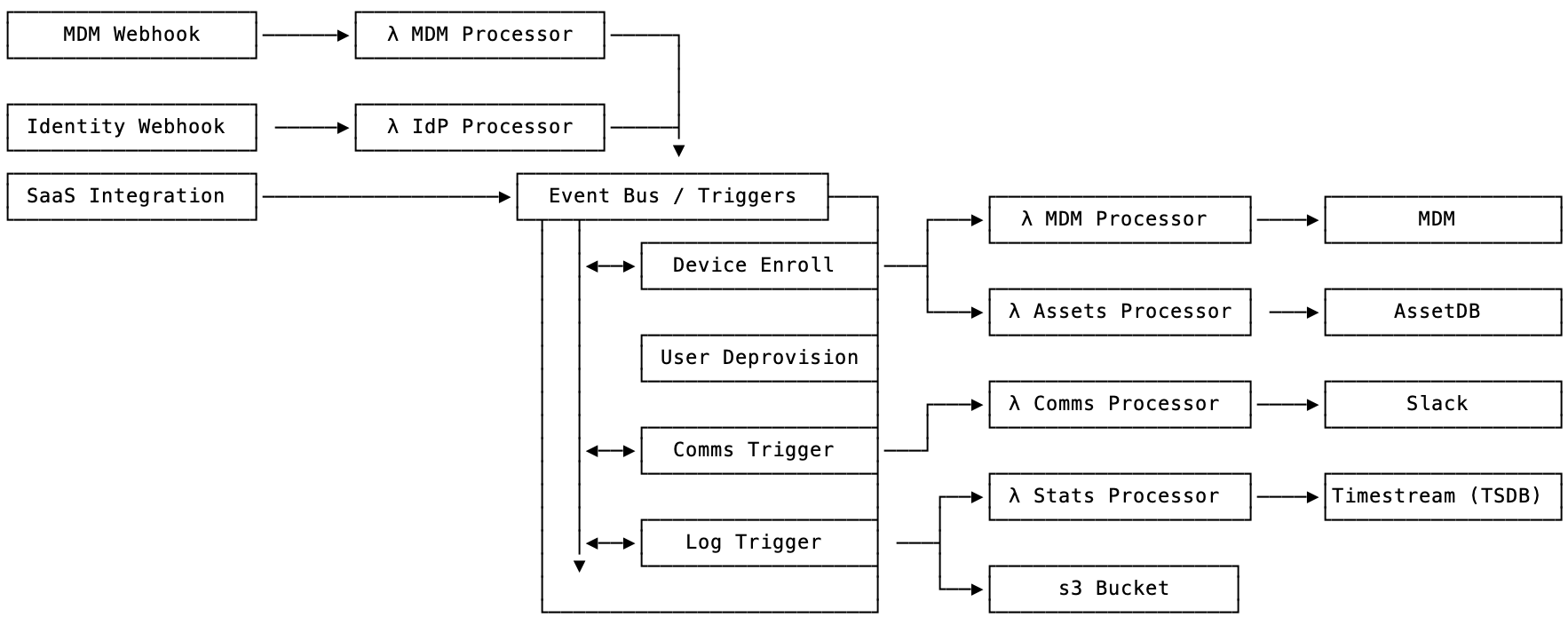
So something to this ☝🏻 design can illustrate the beginning of what I am imagining. A MDM endpoint will send a POST event to an API Gateway endpoint where it will send to the Lambda function to process the event specific to that data source. Those processors generate an event that contains all the needed information for the Event Bridge to process, here’s an over simplified example of an output of the MDM Processor to an event:
{
"scope": "device",
"action": "enroll",
"device": {
"uuid": "someSerial",
},
"communicate": true,
"log": true
}
From this event we can trigger each of these individual Lambda processors that can systematically interact with the upstream services. Looking at the hypothetical triggers:
Device Enrollis triggered asscopeandactionmatch- This process then knows to use some of the information to:
- Update the AssetsDB with device information, such as enrollment state and time
- Update the MDM with any Asset specific notes or device name from the AssetsDB from above
- This process then knows to use some of the information to:
User Deprovisionis not triggeredComms Triggeris triggered ascommunicateistrue- This payload can then be translated to the needed block kit syntax and sent to Slack via a Lambda function that contains all the needed information to interact with Slack via the SDK, Bolt Python etc
Log Triggeris triggered aslogistrue- Send the log to a specific s3 bucket as described in the trigger
- Send the log to
stats processorthat could translate the basic event, device enrolled to a time series data point then sent off to AWS Timestream for later analysis via the managed TSDB (time series database)
Wait, MDM Processor is on that illustration twice? Yes. With this in theory you can have as specific services as you’d like to handle this processes. I envision each processor emoting its own events, if for nothing else then centralized logging and statistics around these duties they are performing, such as:
{
"scope": "communicate",
"action": "slack_post",
"info": {
"channel": "someChanel",
"body": "someText",
"triggering_event": "someEvent",
},
"log": true
}
Now we will systematically aggregate logs in a logical fashion as well as be able to create time series data specific to the usage of any of these micro services as they are consumed. cool 😎
User Deactivation
Identity Provider processor as well! So something like:
{
"scope": "user",
"action": "deactivated",
"log": true
}
This event could trigger an MDM Processor event to lookup the user’s assigned devices and automatically deactivate or lock (depending on your use case) when a user becomes deactivated.
SaaS Partners
I included an ambiguous item on the diagram “SaaS Support” simple because Event Bridge supports SaaS integrations, such as (but not limited too):
- SalesForce via AppFlow
- Auth0
- Datadog
- New Relic
- Zendesk
Which allows for the skipping of the event ingestion and allows for these SaaS Partners to send information directly to your event bus. Not super helpful in the world of system administration, but time will lend to seeing if the adaptation of this integration continues.
Conclusion
As services become dispersed, information becomes harder to aggregate, system administrators are seeing those sources of truth in various locations, a single database with all the things would be amazing, but a far cry from reality.
I think an event driven client endpoint ecosystem allows for the inflexibility of these dispersed services to be aggregated by events initially, triggering downstream events and actions. An event driven architecture is something I’ve thought about in the past, triggering scripts and items from syslog servers, but it was always strenuous with a large amount of work and overhead. Not that an Event Bridge based system isn’t, it just feels more accessible as this, to some degree, is what it was designed to do… for sysadmins? probably not. But our services, infrastructure and systems need to follow suit with the direction of the industry if we want to stay flexible and scalable.
In Casablanca there is a conversation between Major Strasser (an Officer of the Luftwaffe) and Captain Renault (captain of police in Casablanca) that goes like this:
Strasser: I’m not entirely sure which side you’re on.
Renault: I have no conviction, if that’s what you mean. I blow with the wind, and the prevailing wind happens to be from Vichy.
Strasser: And if it should change?
Renault: Well, surely the Reich doesn’t permit that possibility.
I wouldn’t say I have no conviction, but I resonate with Renault’s sentiment here, in my little town, I only have the control over the systems I am permitted, and I have to do what I can to better that environment within the bounds of the “prevailing wind”, be it trends in SaaS services, changes to the MDM Specification or shifting sands of internal tooling and processes.
Thus concludes this ramble under the guise of a thought experiment.
Some References
Apple MDM
AWS EventBridge
AWS Lambda
AWS CloudWatch
AWS S3
JSON Schema